Current Projects: gesture/action recognition, hand tracking and segmentation
1. One-shot Learning Gesture recognition from RGB-D Data Using Bag of Features
Abstract: For one-shot learning gesture recognition, two important challenges are: how to extract distinctive features and how to learn a discriminative model from only one training sample per gesture class. For feature extraction, a new spatio-temporal feature representation called 3D enhanced motion scale-invariant feature transform (3D EMoSIFT) is proposed, which fuses RGB-D data. Compared with other features, the new feature set is invariant to scale and rotation, and has more compact and richer visual representations. For learning a discriminative model, all features extracted from training samples are clustered with the k-means algorithm to learn a visual codebook. Then, unlike the traditional bag of feature (BoF) models using vector quantization (VQ) to map each feature into a certain visual codeword, a sparse coding method named simulation orthogonal matching pursuit (SOMP) is applied and thus each feature can be represented by some linear combination of a small number of codewords. Compared with VQ, SOMP leads to a much lower reconstruction error and achieves better performance. The proposed approach has been evaluated on ChaLearn gesture database and the result has been ranked amongst the top best performing techniques on ChaLearn gesture challenge (round 2).
1. One-shot Learning Gesture recognition from RGB-D Data Using Bag of Features
Abstract: For one-shot learning gesture recognition, two important challenges are: how to extract distinctive features and how to learn a discriminative model from only one training sample per gesture class. For feature extraction, a new spatio-temporal feature representation called 3D enhanced motion scale-invariant feature transform (3D EMoSIFT) is proposed, which fuses RGB-D data. Compared with other features, the new feature set is invariant to scale and rotation, and has more compact and richer visual representations. For learning a discriminative model, all features extracted from training samples are clustered with the k-means algorithm to learn a visual codebook. Then, unlike the traditional bag of feature (BoF) models using vector quantization (VQ) to map each feature into a certain visual codeword, a sparse coding method named simulation orthogonal matching pursuit (SOMP) is applied and thus each feature can be represented by some linear combination of a small number of codewords. Compared with VQ, SOMP leads to a much lower reconstruction error and achieves better performance. The proposed approach has been evaluated on ChaLearn gesture database and the result has been ranked amongst the top best performing techniques on ChaLearn gesture challenge (round 2).
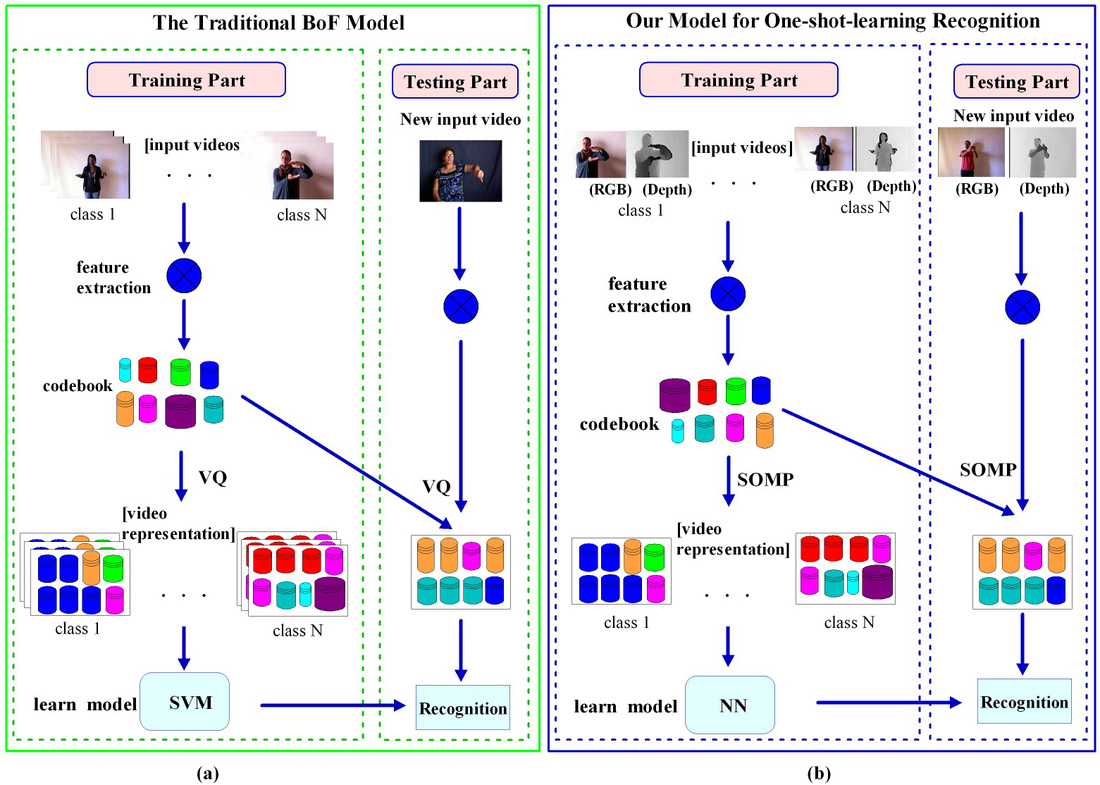 (a) An overview of traditional BoF model ; (b) An overview of our model.
(a) An overview of traditional BoF model ; (b) An overview of our model.
The key contributions of the proposed method are summarized as follows:
Jun Wan, Qiuqi Ruan, Shuang Deng and Wei Li "One-shot Learning Gesture Recognition from RGB-D Data Using Bag of Features", journal of machine learning research (JMLR), pp. 2549-2582, Vol 14, 2013. [PDF] [code]
- 3D EMoSIFT is proposed.
- 3D EMoSIFT is invariant to scale and rotation.
- 3D EMoSIFT is not sensitive to slight motion.
- Using SOMP instead of VQ in the coding stage.
- Obtained high ranking results on ChaLearn gesture challenge.
Jun Wan, Qiuqi Ruan, Shuang Deng and Wei Li "One-shot Learning Gesture Recognition from RGB-D Data Using Bag of Features", journal of machine learning research (JMLR), pp. 2549-2582, Vol 14, 2013. [PDF] [code]
2. 3D SMoSIFT: three-dimensional sparse motion scale invariant feature transform for activity recognition from RGB-D videos
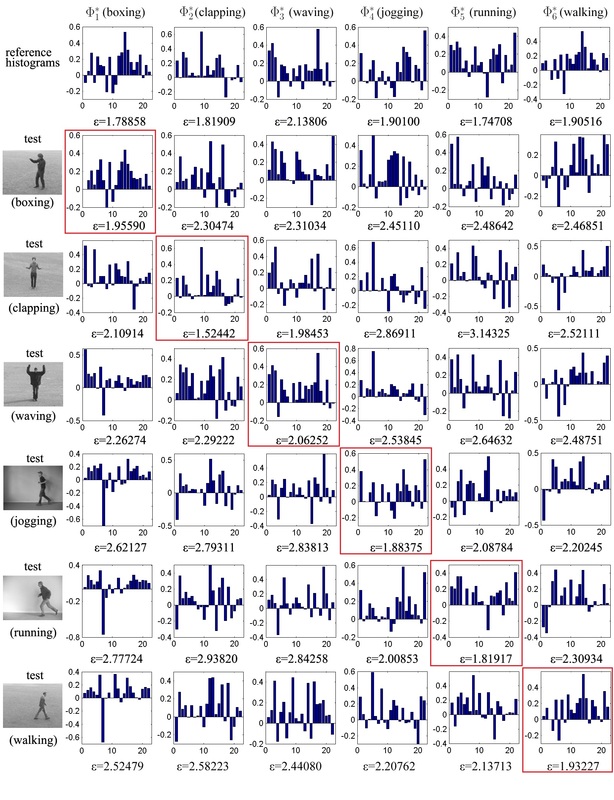
Abstract: Human activity recognition based on RGB-D data has received more attention in recent years. We propose a spatiotemporal feature named three-dimensional (3D) sparsemotion scale-invariant feature transform (SIFT) from RGB-D data for activity recognition. First, we build pyramids as scale space for each RGB and depth frame, and then use Shi-Tomasi corner detector and sparse optical flow to quickly detect and track robust keypoints around the motion pattern in the scale space. Subsequently, local patches around keypoints, which are extracted from RGB-D data, are used to build 3D gradient and motion spaces. Then SIFT-like descriptors are calculated on both 3D spaces, respectively. The proposed feature is invariant to scale, transition, and partial occlusions. More importantly, the running time of the proposed feature is fast so that it is well-suited for real-time applications. We have evaluated the proposed feature under a bag of words model on three public RGB-D datasets: one-shot learning Chalearn Gesture Dataset, Cornell Activity Dataset-60, and MSR Daily Activity 3D dataset. Experimental results show that the proposed feature outperforms other spatiotemporal features and are comparative to other state-of-the-art approaches, even though there is only one training sample for each class.
Abstract: Human activity recognition based on RGB-D data has received more attention in recent years. We propose a spatiotemporal feature named three-dimensional (3D) sparsemotion scale-invariant feature transform (SIFT) from RGB-D data for activity recognition. First, we build pyramids as scale space for each RGB and depth frame, and then use Shi-Tomasi corner detector and sparse optical flow to quickly detect and track robust keypoints around the motion pattern in the scale space. Subsequently, local patches around keypoints, which are extracted from RGB-D data, are used to build 3D gradient and motion spaces. Then SIFT-like descriptors are calculated on both 3D spaces, respectively. The proposed feature is invariant to scale, transition, and partial occlusions. More importantly, the running time of the proposed feature is fast so that it is well-suited for real-time applications. We have evaluated the proposed feature under a bag of words model on three public RGB-D datasets: one-shot learning Chalearn Gesture Dataset, Cornell Activity Dataset-60, and MSR Daily Activity 3D dataset. Experimental results show that the proposed feature outperforms other spatiotemporal features and are comparative to other state-of-the-art approaches, even though there is only one training sample for each class.
The key contributions of the proposed method are summarized as follows:
[1] Jun Wan, Qiuqi Ruan, Shuang Deng and Wei Li "One-shot Learning Gesture Recognition from RGB-D Data Using Bag of Features", journal of machine learning research (JMLR), pp. 2549-2582, vol 14, 2013. [PDF] [code]
[2] Jun Wan, Qiuqi Ruan, Wei Li, Gaoyun An and Ruizhen Zhao, "3D SMoSIFT: Three-dimensional Sparse Motion Scale Invariant Feature Transform for Activity Recognition from RGB-D Videos", Journal of Electronic Imaging, 23(2), 023017, 2014. [PDF] [code] http://dx.doi.org/10.1117/1.JEI.23.2.023017
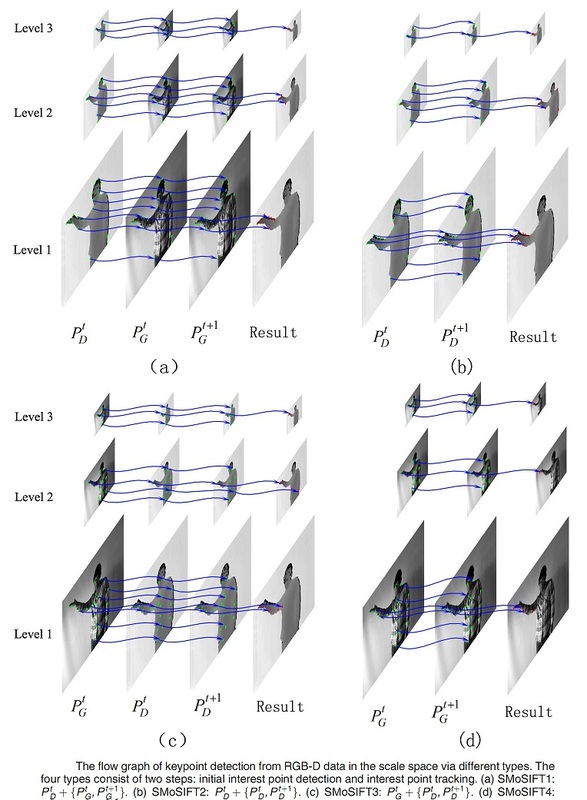
- For 3D (E)MoSIFT feature, it first builds Gaussian pyramid and difference of Gaussian (DoG) pyramid to find local extrema points. As each point in DoG pyramid should be compared to its 26 neighbors in 3 × 3 regions at the current and adjacent scales, it will cost much time to detect all keypoints. However, we propose a novel method to detect keypoints via simple corner detector and the tracking technique. Due to only some corner points being considered, the keypoint detection is sparse. That is why the new feature is called 3D SMoSIFT.
- We know that 3D (E)MoSIFT consists of gradient and motion features. From experimental results of 3D EMoSIFT, the authors proved that the performance of motion features is less than that of gradient features. That is probably because depth frames are often contaminated with undefined depth points, which appear in the sequence as spatially and temporally Discontinuous black regions. The missing depth points may affect the motion feature. So we extract the local patches around keypoint regions and smooth them using Gaussian filter. Besides, the 3D modified motion space is proposed to calculate motion features.
- 3D SMoSIFT is invariant to scale, transition, and partial occlusions.
- Compared with 3D (E)MoSIFT, which is time-consuming, 3D SMoSIFT can be applied in real-time applications.
- The proposed feature has obtained high performances on some human activity datasets, such as Chalearn Gesture Dataset, Cornell Activity Dataset-60, and MSR Daily Activity 3D Dataset.
[1] Jun Wan, Qiuqi Ruan, Shuang Deng and Wei Li "One-shot Learning Gesture Recognition from RGB-D Data Using Bag of Features", journal of machine learning research (JMLR), pp. 2549-2582, vol 14, 2013. [PDF] [code]
[2] Jun Wan, Qiuqi Ruan, Wei Li, Gaoyun An and Ruizhen Zhao, "3D SMoSIFT: Three-dimensional Sparse Motion Scale Invariant Feature Transform for Activity Recognition from RGB-D Videos", Journal of Electronic Imaging, 23(2), 023017, 2014. [PDF] [code] http://dx.doi.org/10.1117/1.JEI.23.2.023017
3. CSMMI: Class-Specific Maximization of Mutual Information for Action and Gesture Recognition
Abstract: In this pa per, we propose a novel approach called CSMMI using a submodular method, which aims at learning a compact and discriminative dictionary for each class. Unlike traditional dictionary-based algorithms, which typically learn a shared dictionary for all of the classes, we unify the intra-class and inter-class mutual information (MI) into an single objective function to optimize class-specific dictionary. The objective function has two aims: (1) Maximizing the MI between dictionary items within a specific class (intrinsic structure); (2) Minimizing the MI between the dictionary items in a given class and those of the other classes (extrinsic structure). We significantly reduce the computational complexity of CSMMI by introducing an novel submodular method, which is one of the important contributions of this paper. Our paper also contributes a state-of-the-art end-to-end system for action and gesture recognition incorporating CSMMI, with feature extraction, learning initial dictionary per each class by sparse coding, CSMMI via submodularity and classification based on reconstruction errors. We performed extensive experiments on synthetic data and eight benchmark datasets. Our experimental results show that CSMMI outperforms shared dictionary methods and that our end-to-end system is competitive with other state-of-the-art approaches.
Abstract: In this pa per, we propose a novel approach called CSMMI using a submodular method, which aims at learning a compact and discriminative dictionary for each class. Unlike traditional dictionary-based algorithms, which typically learn a shared dictionary for all of the classes, we unify the intra-class and inter-class mutual information (MI) into an single objective function to optimize class-specific dictionary. The objective function has two aims: (1) Maximizing the MI between dictionary items within a specific class (intrinsic structure); (2) Minimizing the MI between the dictionary items in a given class and those of the other classes (extrinsic structure). We significantly reduce the computational complexity of CSMMI by introducing an novel submodular method, which is one of the important contributions of this paper. Our paper also contributes a state-of-the-art end-to-end system for action and gesture recognition incorporating CSMMI, with feature extraction, learning initial dictionary per each class by sparse coding, CSMMI via submodularity and classification based on reconstruction errors. We performed extensive experiments on synthetic data and eight benchmark datasets. Our experimental results show that CSMMI outperforms shared dictionary methods and that our end-to-end system is competitive with other state-of-the-art approaches.
The main contributions of this paper are:
Jun Wan, Vassilis Athitsos, Pat Jangyodsuk, Hugo Jair Escalante, Qiuqi Ruan, and Isabelle Guyon "CSMMI: Class-Specific Maximization of Mutual Information for Action and Gesture Recognition", IEEE Transactions on Image Processing,vol 23(7), pp.3152-3165, 2014 .
- CSMMI unifies the intra-class and inter-class MI into an objective function to seek one class-specific dictionary per each class. The objective function includes two parts. The first is the intrinsic structure to keep MMI between the selected dictionary items and the rest of dictionary items in a specific class. The second is the extrinsic structure to keep minimization of mutual information (mMI) between the selected dictionary items in a specific class and the dictionary items of other classes. The aim of CSMMI is to select the dictionary items that are highly correlated to a specific class and less correlated to other classes.
- Because of the high computational complexity of CSMMI, we propose submodularity to calculate the class-specific dictionary. Compared with the primitive complexity O(kC^5K^4), the complexity of submodularity is only O(kC^2K^4), where K is the initial dictionary size; C is the number of classes and k (k < K) is the number of selected dictionary items from an initial dictionary.
- Because each class has one dictionary, we can execute class-specific dictionaries in a parallel to speed up the processing time in the recognition stage. Besides, in the initial class-specific dictionary learning stage, each action class is modeled independently of the others and hence the painful repetition of the training process when a new class is added is no longer necessary.
Jun Wan, Vassilis Athitsos, Pat Jangyodsuk, Hugo Jair Escalante, Qiuqi Ruan, and Isabelle Guyon "CSMMI: Class-Specific Maximization of Mutual Information for Action and Gesture Recognition", IEEE Transactions on Image Processing,vol 23(7), pp.3152-3165, 2014 .
4. Hand Tracking and Segmentation
Abstract: Segmenting human hand is important in computer vision applications, e.g. sign language interpretation, human computer interaction and gesture recognition. However, some serious bottlenecks still exist in hand localization systems such as fast hand motion capture, hand over face and hand occlusions which we focus on in this paper. We present a novel method for hand tracking and segmentation based on augmented graph cuts and dynamic model. First, an effective dynamic model for state estimation is generated, which correctly predicts the location of hands probably having fast motion or shape deformations. Second, new energy terms are brought into the energy function to develop augmented graph cuts based on some cues, namely spatial information, hand motion and chamfer distance. The proposed method successfully achieves hand segmentation even though the hand passes over other skin-colored objects. Some challenging videos are provided in the case of hand over face, hand occlusions, dynamic background and fast motion. Experimental results demonstrate that the proposed method is much more accurate than other graph cuts-based methods for hand tracking and segmentation.
Abstract: Segmenting human hand is important in computer vision applications, e.g. sign language interpretation, human computer interaction and gesture recognition. However, some serious bottlenecks still exist in hand localization systems such as fast hand motion capture, hand over face and hand occlusions which we focus on in this paper. We present a novel method for hand tracking and segmentation based on augmented graph cuts and dynamic model. First, an effective dynamic model for state estimation is generated, which correctly predicts the location of hands probably having fast motion or shape deformations. Second, new energy terms are brought into the energy function to develop augmented graph cuts based on some cues, namely spatial information, hand motion and chamfer distance. The proposed method successfully achieves hand segmentation even though the hand passes over other skin-colored objects. Some challenging videos are provided in the case of hand over face, hand occlusions, dynamic background and fast motion. Experimental results demonstrate that the proposed method is much more accurate than other graph cuts-based methods for hand tracking and segmentation.
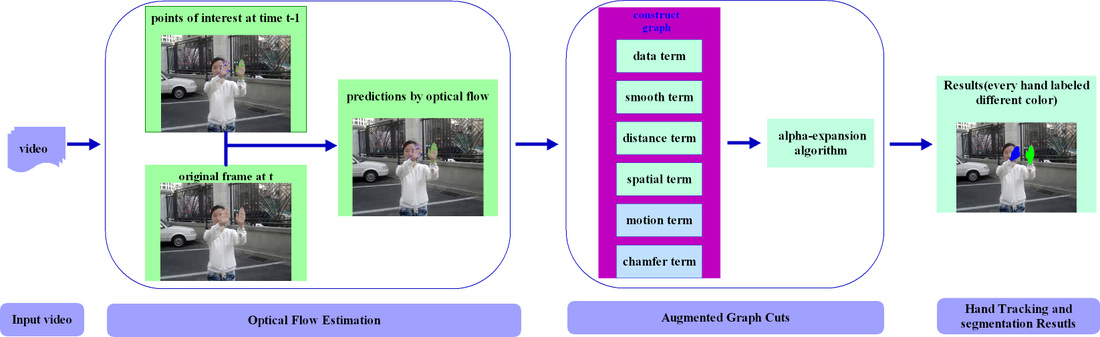
The flow chart of the propose method for hand tracking and segmentation
|
If you use this paper, please cite:
[1] Jun Wan, Qiuqi Ruan, Gaoyun An, Wei Li "Hand tracking and segmentation via graph cuts and dynamic model in sign language videos", Signal Processing (ICSP), IEEE 11th International Conference on, pp. 1135-1138, 2012. [2] Jun Wan, Qiuqi Ruan, Gaoyun An, Wei Li, Yanyan Liang, and Ruizhen Zhao, "The Dynamic Model Embed in Augmented Graph Cuts for Robust Hand Tracking and Segmentation in Videos," Mathematical Problems in Engineering, vol. 2014, Article ID 320141, 12 pages, 2014. doi:10.1155/2014/320141 |
Here, we give some experimental results by our method. Alternately, you can download the results [results download] and the source videos can be found [source videos download].
If you cannot open the next sixe videos, please install Adobe Flash Player.
If you cannot open the next sixe videos, please install Adobe Flash Player.
One hand tracking and segemtation |
Hand tracking (hand occlusions) |
Hand over face |
Purdue sign language video tracking |
hand tracking and segmentation(dynamic background) |
hand tracking and segmentation
|
Previous project:
1. Using two methods for recognition common carotid artery of B-mode longitudinal ultrasound image
Abstract: In this paper two novel methods are proposed for recognizing B-mode ultrasound (US) imaging of common carotid artery (CCA) in longitude. In the single frame method, the US is segmented by k-means fuzzy clustering algorithm. Then a series points are extracted based on geometric features. Thirdly, the feature points are selected according to our new cluster method. Then curve fitting is applied by feature points. Finally CCA is recognized in US imaging. According to the experiment on 7402 frames of 104 US videos from different persons, 95.66% accuracy rate is achieved. Based on multi-frame algorithm, it integrates the first algorithm for present frame and a buffer strategy for previous frame information. 98.97% accuracy rate is higher than the single frame method. Our novel technique outperforms the current technique proposed in other papers. The recognition CCA is totally automatic in our database by our proposed methods. Those proposed automatic methods are suitable for real-time recognition of the CCA.
1. Using two methods for recognition common carotid artery of B-mode longitudinal ultrasound image
Abstract: In this paper two novel methods are proposed for recognizing B-mode ultrasound (US) imaging of common carotid artery (CCA) in longitude. In the single frame method, the US is segmented by k-means fuzzy clustering algorithm. Then a series points are extracted based on geometric features. Thirdly, the feature points are selected according to our new cluster method. Then curve fitting is applied by feature points. Finally CCA is recognized in US imaging. According to the experiment on 7402 frames of 104 US videos from different persons, 95.66% accuracy rate is achieved. Based on multi-frame algorithm, it integrates the first algorithm for present frame and a buffer strategy for previous frame information. 98.97% accuracy rate is higher than the single frame method. Our novel technique outperforms the current technique proposed in other papers. The recognition CCA is totally automatic in our database by our proposed methods. Those proposed automatic methods are suitable for real-time recognition of the CCA.
|
|
If you use this paper, please cite: [1] Jun Wan, Qiuqi Ruan, Wei Li "Using two methods for recognition common carotid artery of B-mode longitudinal ultrasound image", Signal Processing (ICSP), IEEE 10th International Conference on, pp. 1-4, 2010. [2] Jun Wan, Qiuqi Ruan, Yingchun Li "A New Method of Automatic Recognition of B-Mode Ultrasound Imaging of Common Carotid Artery in Longitude", Bioinformatics and Biomedical Engineering, 4th International Conference on, pp.1-4, 2010. |
Publications
(my google scholar citations)
Journal:
(my google scholar citations)
Journal:
- [1] Jun Wan, Qiuqi Ruan, Shuang Deng and Wei Li "One-shot Learning Gesture Recognition from RGB-D Data Using Bag of Features", Journal of Machine Learning Research (JMLR), pp. 2549-2582, vol 14, 2013. [PDF] [code] (SCI, IF:3.42)
- [2] Jun Wan, Vassilis Athitsos, Pat Jangyodsuk, Hugo Jair Escalante, Qiuqi Ruan, and Isabelle Guyon "CSMMI: Class-Specific Maximization of Mutual Information for Action and Gesture Recognition", IEEE Transactions on Image Processing (TIP), vol 23(7), pp.3152-3165, 2014 . [PDF] (SCI, IF:3.19)
- [3] Jun Wan, Qiuqi Ruan, and Wei Li, "3D SMoSIFT: Three-dimensional Sparse Motion Scale Invariant Feature Transform for Activity Recognition from RGB-D Videos", Journal of Electronic Imaging, 23(2), 023017, 2014. [PDF] [code] (SCI, IF:1.06)
- [4] Jun Wan, Qiuqi Ruan, Gaoyun An, Wei Li, Yanyan Liang, and Ruizhen Zhao, "The Dynamic Model Embed in Augmented Graph Cuts for Robust Hand Tracking and Segmentation in Videos," Mathematical Problems in Engineering, vol. 2014, Article ID 320141, 12 pages, 2014. doi:10.1155/2014/320141. You can download the results [download]. Alternately, you can see experimental results in my project 4 ("Hand Tracking and Segmentation"), (SCI,IF:1.08).
- [5] Wei Li, Qiuqi Ruan, Jun Wan "Graph-preserving shortest feature line segment for dimensionality reduction", Neurocomputing, vol 110, pp 80-91, 2013. [PDF] (SCI, IF:1.634)
- [6] Wei Li, Qiuqi Ruan, Jun Wan "Dimensionality Reduction Using Graph-embedded Probability-based Semi-supervised Discriminant Analysis", Neurocomputing, 2014 (In Press). [PDF] (SCI, IF:1.634)
- [7] Wei Li, Qiuqi Ruan, Jun Wan "Semi-supervised dimensionality reduction using estimated class membership probabilities", Journal of Electronic Imaging, vol 21(4), 043010, 2012. [PDF] (SCI, IF:1.06)
- [8] Wei Li, Qiuqi Ruan, Jun Wan "Fuzzy Nearest Feature Line-based Manifold Embedding for Facial Expression Recognition", Journal of Information Science and Engineering, vol 20, no 2, pp 329-346, 2013. [PDF] (SCI, IF:0.299)
Conference( list sorted by year ):
Other papers:
- [1] Jun Wan, Qiuqi Ruan, Yingchun Li "A New Method of Automatic Recognition of B-Mode Ultrasound Imaging of Common Carotid Artery in Longitude", Bioinformatics and Biomedical Engineering, 4th International Conference on, pp.1-4, 2010.
- [2] Jun Wan, Qiuqi Ruan, Wei Li "Using two methods for recognition common carotid artery of B-mode longitudinal ultrasound image", Signal Processing (ICSP), IEEE 10th International Conference on, pp. 1-4, 2010.
- [3] Wei Li, Qiuqi Ruan, Jun Wan "Two-dimensional uncorrelated linear discriminant analysis for facial expression recognition", Signal Processing (ICSP), IEEE 10th International Conference on, pp. 1362-1365, 2010.
- [4] Jun Wan, Qiuqi Ruan, Gaoyun An, Wei Li "Hand tracking and segmentation via graph cuts and dynamic model in sign language videos", Signal Processing (ICSP), IEEE 11th International Conference on, pp. 1135-1138, 2012.
- [5] Jun Wan, Qiuqi Ruan, Gaoyun An, Wei Li "Gesture recognition based on Hidden Markov Model from sparse representative observations", Signal Processing (ICSP), IEEE 11th International Conference on, pp. 1180-1183, 2012.
- [6] Wei Li, Qiuqi Ruan, Gaoyun An, Jun Wan "Feature extraction of multimodal data by cluster-based correlation discriminative analysis", Signal Processing (ICSP), IEEE 11th International Conference on, pp. 797-800, 2012.
- [7] Wei Li, Qiuqi Ruan, Gaoyun An, Jun Wan "Discriminative uncorrelated neighborhood preserving projection for facial expression recognition", Signal Processing (ICSP), IEEE 11th International Conference on, pp. 801-805, 2012.
Other papers:
- [1] Hugo Jair Escalante, Isabelle Guyon, Vassilis Athitsos, Pat Jangyodsuk, Jun Wan, "Principal motion components for gesture recognition using a single-example", arXiv preprint arXiv:1310.4822, 2013. [PDF]
